Squeeze-and-Excitation Networks
“Let’s add parameters to each channel of a convolutional block so that the network can adaptively adjust the weighting of each feature map.”
Why
CNNs use their convolutional filters to extract information from images. Lower layers find trivial pieces of context like edges or high frequencies, while upper layers can detect faces, text or other complex geometrical shapes. They extract whatever is necessary to solve a task efficiently.
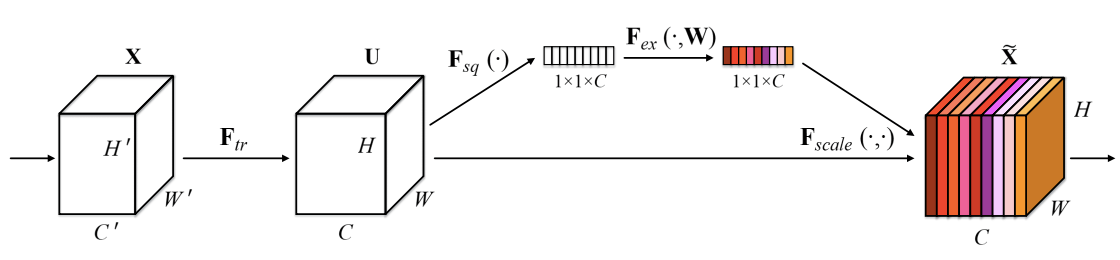
Before the apperance of this paper, CNN often use many kernel to extract information from a input, and the network weights each of its channels equally when creating the output feature maps. It someway cannot make impression for the important channels.SENets are all about changing this by adding a content aware mechanism (cơ chế nhận biết thông tin) to weight each channel adaptively. In it’s most basic form this could mean adding a single parameter to each channel and giving it a linear scalar how relevant each one is (In short, it will weight for each channel in a features).
How
All it need to do simply add a SE-Block after the feature map so that it can make an impression for the important channels of feature map.
def se_block(in_block, ch, ratio=16):
x = GlobalAveragePooling2D()(in_block)
x = Dense(ch//ratio, activation='relu')(x)
x = Dense(ch, activation='sigmoid')(x)
return multiply()([in_block, x])
These additional layers add almost no additional computation cost (about 0.26% GFLOPs of ResNet-50 as author’s experiment). The authors show that by adding SE-blocks to ResNet-50 it can expect almost the same accuracy as ResNet-101 delivers. This is impressive for a model requiring only half of the computational costs.
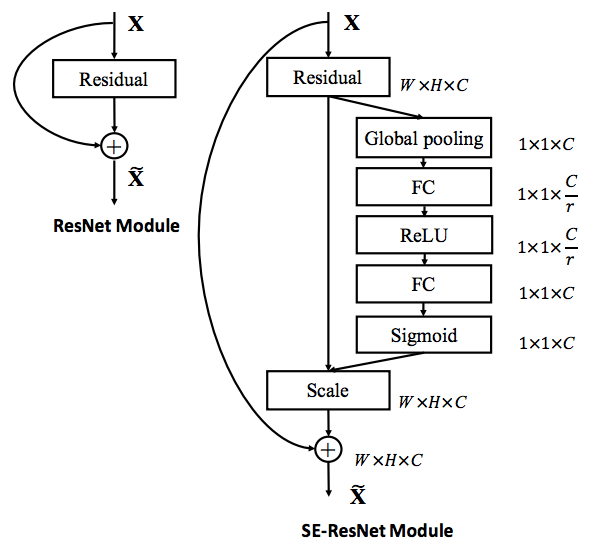
When put SE-blocks to resnet, we have SE-resnet, it can be shown like that bellow:

Result
The paper further investigates other architectures like Inception, Inception-ResNet and ResNeXt. The latter leads them to a modified version that shows a top-5 error of 3.79% on ImageNet.
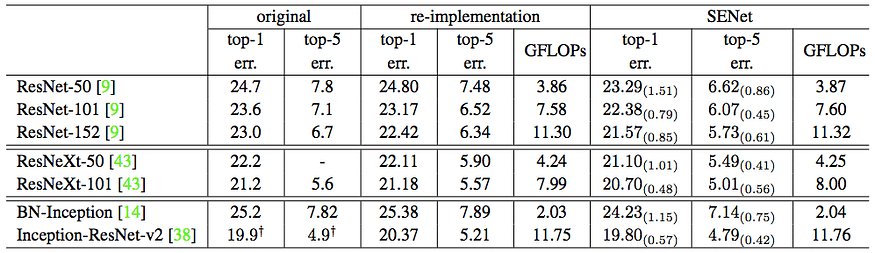
What amazes me the most about SENets is just how simple and yet effective they are. Being able to add this approach to any model at almost no cost, should make you jump back to the drawing board and retraining everything you ever built.
Reference
https://bit.ly/2VwK9iX
https://arxiv.org/pdf/1709.01507.pdf